




Location: Remote
Experience: 5+ years working with speech technologies including STT, diarization, and speech translation
Compensation: Competitive
Adalat AI
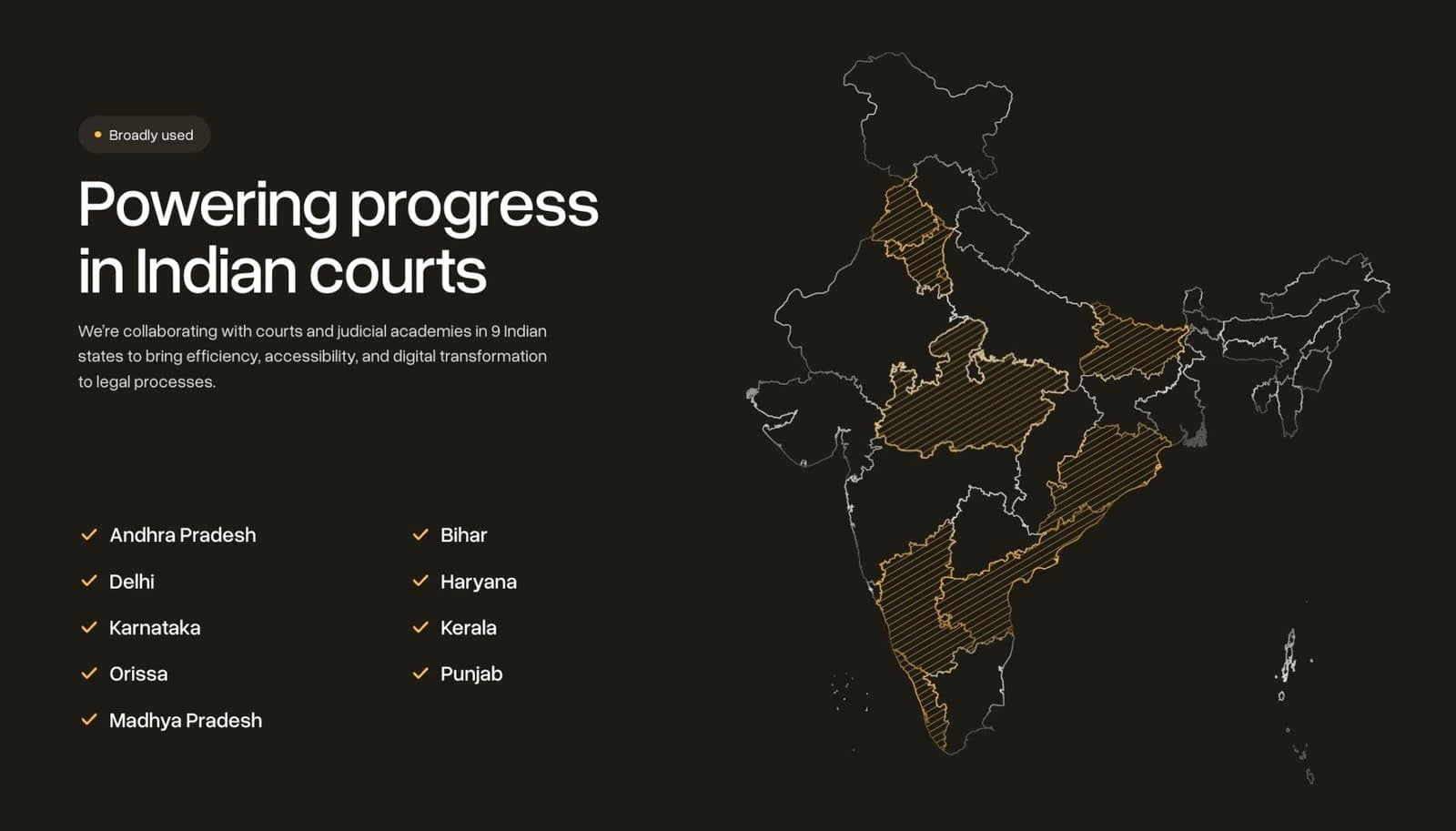
When India's courts struggled with mounting delays and inefficiencies, a team of legal and technology experts from Harvard, Oxford, MIT, and IIIT Hyderabad saw an opportunity for transformation. Adalat AI emerged as a legal-tech startup building India's end-to-end justice tech stack, using artificial intelligence to eliminate judicial delays and enhance access to justice. Operating across 10 Indian states with backing from world-leading foundations, their solutions include cutting-edge ASR models for Indian languages successfully implemented in multiple high courts, including a landmark deployment at Delhi High Court.
Role
Join Adalat AI's mission to transform India's judicial system through cutting-edge speech technology. You'll develop state-of-the-art ASR models for Indian languages that are already revolutionising courtrooms across 10 states, including recent deployment at Delhi High Court.
Responsibilities
- Design and implement hybrid and end-to-end speech processing systems using machine learning and deep learning techniques
- Preprocess, annotate, and manage large datasets of speech and text for training multilingual legal domain models
- Develop data augmentation techniques to improve model robustness across regional dialects and legal terminology
- Train and fine-tune speech recognition models using state-of-the-art architectures like wav2vec2, Whisper, and Parakeet
- Build and experiment with hybrid speech recognition systems including GMM-HMM and DNN-HMM frameworks
- Conduct rigorous evaluation of speech models and implement feedback loops for continuous improvement
- Collaborate with product managers and engineers to translate user requirements into technical solutions
- Ensure compliance with data privacy and security regulations across all projects
- Document research findings and communicate progress effectively to stakeholders and academic partners
- Stay current with latest developments in speech recognition and exchange knowledge with team members
Requirements
- 5+ years of experience working with speech technologies including STT, diarization, and speech translation
- Deep knowledge of ASR, multilingual speech recognition, language models, and audio classification
- Hands-on experience building hybrid speech recognition systems (GMM-HMM, DNN-HMM)
- Expertise with end-to-end speech recognition using modern architectures
- Proficiency in machine learning libraries (Scikit Learn, TensorFlow, PyTorch)
- Strong programming skills in Python, C/C++, and shell scripting
- Bachelor's or Master's in Computer Science, Electrical Engineering, or related field (preferred)
- Research publications at conferences or journals (preferred)
Benefits
- Remote work with flexible hours
- Unlimited PTO and generous vacation
- Autonomy and ownership in role
- Learning and development opportunities
- Access to Harvard/MIT/Oxford networks
- Maternity and paternity leave
- Collaborative team environment
Apply
To apply, please send your resume and a cover letter with the subject line: "ML Researcher - Speech".
Find more AI & ML roles!



